반응형
개 념
문자열 탐색 (원시적 탐색, 카프라빈 탐색, KMP탐색, 보이어 무어 탐색) 문자열 데이터 안에서 특정 패턴의 검색 대상이 되는 문자열을 탐색하는 알고리즘
I. 문자열 탐색의 개요
가. 문자열 탐색의 정의
- 문자열 데이터 안에서 특정 패턴의 검색 대상이 되는 문자열을 탐색하는 알고리즘
Ⅱ. 문자열 탐색 알고리즘
가. 원시적 탐색
* 특정 대상의 문자열에서 찾고자 하는 패턴 문자를 탐색하는 기법 * 주어진 텍스트에서 주어진 패턴이 어디에 나타나는지 알아내는 문제 |
 |
BasicStringMatching(A[ ], P[ ], n, m) { /* n: 배열 A[ ]의 길이, m: 배열 P[ ]의 길이 */ for (i = 0; i ≤ n-m; i++) { for (j == 0; j < m; j++) { if ( P[j] != T[i + j] ) break; } if (j == m) printf (“패턴이 텍스트의 i번째 문자부터 나타남”); } } |
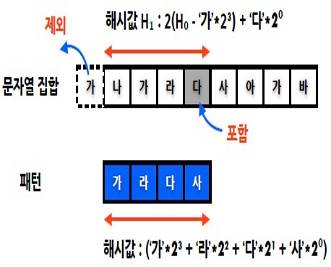
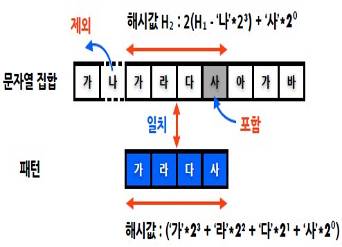
나. 카프라빈 탐색
* 문자열 패턴을 수치로 변환하여 탐색하는 알고리즘 * 해시값을 활용하여 비교를 수행하는 방법 * 문자열 집합과 패턴 길이의 크기에 따라 해시 크기가 매우 커질 수 있음. * 나머지 연산을 통해 해시 크기를 제한 |
||||
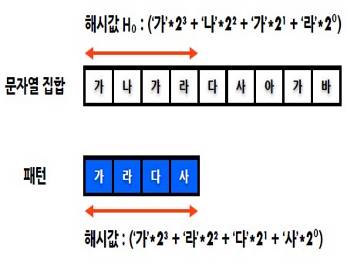 |
⇒ |  |
⇒ |  |
 |
||||
#include char s[1000]={0},p[100]={0}; int slen,plen,q=113,pkey=0,a[1000]={0},tenp=1; int main() { int i,j; bool check; scanf("%s",s); scanf("%s",p); slen=strlen(s),plen=strlen(p); for(i=0;i < plen;i++) pkey*=10,pkey%=q,pkey+=p[i]; for(i=0;i < plen;i++) a[0]*=10,a[0]%=q,a[0]+=s[i]; for(i=1;i < plen;i++) tenp*=10,tenp%=q; for(i=1;i < slen-plen;i++) { a[i]=(a[i-1]-tenp*s[i-1]+q)%q+s[i+plen-1]; if(a[i]==p[i]) { check=true; for(j=0;j < plen;j++) { if(p[j]!=s[i+j]) { check=false; break; }} if(check) printf("Matched : %d to %d",i+1,i+plen); } } return 0; } |
||||
다. KMP 탐색
* 문자열 중에 특정 패턴을 찾아서 전처리하여 배열 next[M]을 구해서 검색하는 방법 * next[M]: 불일치가 발생했을 경우, 이동할 다음 위치 * 접두부(문자열Head부분), 접미부(문자열Tail부분), 경계(패턴문자열간 경계)로 나누어짐 |
| Step 1> 패턴이 매칭되지 않으면, next[M]=1 만큼 이동 |
 |
| Step 2> 패턴이 매칭된 문자열인 next[M]=3 만큼 이동 |
 |
| Step 3> 패턴이 매칭되지 않으면, next[M]=1 만큼 이동 |
 |
| Step 4> 일치했던 문자열과 패턴 내에서 반복되는 문자열이 있는 경우, 문자열 일치했던 부분과 패턴의 일치했던 접두부분이 대응되도록 next[M] 이동 |
 |
| Step 5> 마지막 이동 |
 |
// 전처리 부분 void preKmp(char *x, int m, int kmpNext[]) { int i, j; i = 0; j = kmpNext[0] = -1; while (i < m) { while (j > -1 && x[i] != x[j]) j = kmpNext[j]; i++; j++; if (x[i] == x[j]) kmpNext[i] = kmpNext[j]; else kmpNext[i] = j; }} // 탐색 부분 void KMP(char *x, int m, char *y, int n) { int i, j, kmpNext[XSIZE]; preKmp(x, m, kmpNext); i = j = 0; while (j < n) { while (i > -1 && x[i] != y[j]) i = kmpNext[i]; i++; j++; if (i >= m) { OUTPUT(j - i); i = kmpNext[i]; }}} |
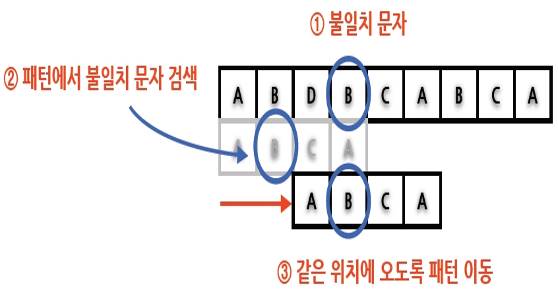
라. 보이어 무어 탐색
* 좌에서 우로 패턴 매칭위치를 탐색하지만 문자비교는 우에서 좌로 행하는 알고리즘 |
||
(1) 불일치 문자 방책 (Bad Character Heuristics) - 패턴에서 불일치가 발생한 문자의 오른쪽에 있는 최대 접미부가 일치하도록 패턴을 오른쪽으로 이동하는 것 |
||
 |
⇒ |  |
(2) 일치 접미부 방책 (Good Suffix Heuristics) - 텍스트에 있는 불일치가 발생한 문자가 패턴의 문자가 일치하도록 오른쪽으로 이동 |
||
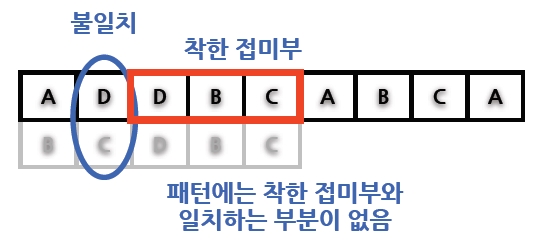 |
⇒ |  |
int BM_Search(String text, String pattern) { int patLen = pattern.length(); //패턴의 길이 int textLen = text.length(); //텍스트와 패턴이 일치하지 않았을 때에 이동 범위 int[] skip = new int[65536]; //정수 최대값 int i, j; //표 skip작성 Arrays.fill(skip, patLen); for (int x = 0; x < patLen -1; x++){ skip[pattern.charAt(x)] = patLen - x - 1; } //포인터를 초기화한다. 패턴을 뒤에서부터 비교하기 때문에 i = patLen - 1; //텍스트의 가장 마지막에 도달할 때까지 반복한다 while (i < textLen) { //포인터 j가 패턴의 마지막 문자를 가리키도록 한다 j = patLen -1; //텍스트와 패턴이 일치하는 동안 반복한다 while (text.charAt(i) == pattern.charAt(j)) { //처음 문자까지 일치했다면 탐색은 성공이다 if (j == 0) {return i;} i--; j--; } i = i + Math.max(skip[text.charAt(i)], patLen - j); }//결국 발견하지 못했을때 return -1; } |
||
[Algorithm] 최단 경로 탐색 알고리즘
개 념최단 경로 탐색 알고리즘 (다익스트라 알고리즘, 벨만-포드 알고리즘, 플로이드(Floyd) 알고리즘, A* 알고리즘) 그래프 내의 한 vertex에서 다른 vertex로 이동할 때 가중치의 합이 최소값이 되는
infoofit.tistory.com
[용어/개념] 프로세스(Process) vs 쓰레드(Thread) 비교 정리
[용어/개념] 프로세스(Process) vs 쓰레드(Thread) 비교 정리
프로세스의 정의- 레지스터(register), 스택(stack), 포인트(point), 프로그램, 데이터 등의 집합체로 실행 중인 프로그램 비 동기적 행위, 프로시저(procedure)가 활동 중인 것, 실행 중인 프로시저의 제어
infoofit.tistory.com
반응형